Unlocking Business Insights from Audio with AWS Transcribe, Comprehend & ELK
Many businesses struggle to gain actionable insights from customer recordings because they are locked in voice and audio files that can’t be analyzed. They have a gold mine of potential information from product feedback, customer service recordings and more, but it’s seemingly locked in a black box.
Until recently, transcribing audio files to text has been time-consuming or inaccurate.
Speech to text is the process of converting speech input into digital text, based on speech recognition. The best solutions were either not accurate enough, too expensive to scale or didn’t play well with legacy analysis tools. With Amazon’s introduction of AWS Transcribe, that has changed.
In this two-part blog post, we are going to present a system architecture to convert audio and voice into written text with AWS Transcribe, extract useful information for quick understanding of content with AWS Comprehend, index this information in Elasticsearch 6.2 for fast search and visualize the data with Kibana 6.2. In Part I, you can learn about the key components, architecture, and common use cases. In Part II, you can learn how to implement this architecture.
We are going to analyze some customer recordings (complaints, product feedbacks, customer support) to extract useful information and answer the following questions:
- How many positive recordings do I have?
- How many customers are complaining (negative feedback) about my products?
- Which is the sentiment about my product?
- Which entities/key phrases are the most common in my recordings?
The components that we are going to use are the following:
- AWS S3 bucket
- AWS Transcribe
- AWS Comprehend
- Elasticsearch 6.2
- Kibana 6.2
- Skedler Reports and Alerts
System architecture:
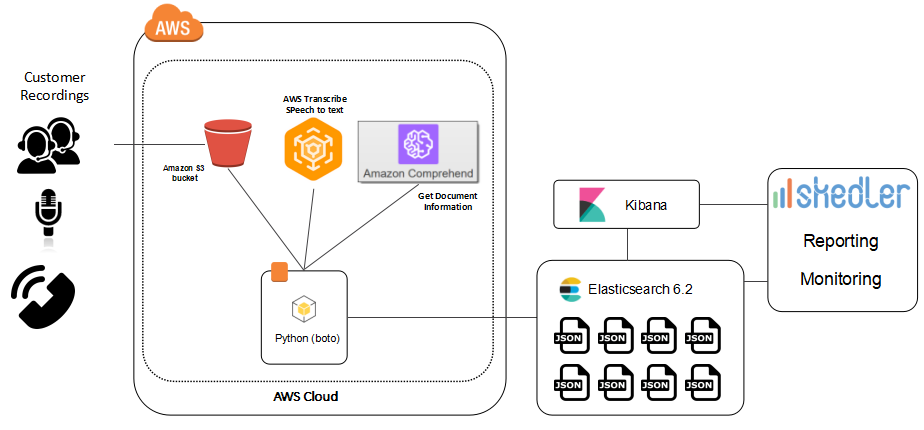
This architecture is useful when you want to get useful insights from a set or audio/voice recording. You will be able to convert to text your recordings, extract semantic details from the text, perform fast search/aggregations on the data, visualize and report the data.
Examples of common applications are:
- transcription of customer service calls
- generation of subtitles on audio and video content
- conversion of audio file (for example podcast) to text
- search for keywords or inappropriate words within an audio file
AWS Transcribe
At the re:invent2017 conference, Amazon Web Services presented Amazon Transcribe, a new, machine learning – natural language processing – service.
![]()
Amazon Transcribe is an automatic speech recognition (ASR) service that makes it easy for developers to add speech to text capability to their applications. Using the Amazon Transcribe API, you can analyze audio files stored in Amazon S3 and have the service return a text file of the transcribed speech.
Instead of AWS Transcribe, you can use similar services to perform speech to text analysis, like: Azure Bing Speech API or Google Cloud Speech API.
> The service is still in preview, watch the launch video here: AWS re:Invent 2017: Introducing Amazon Transcribe.
> You can read more about it here: Amazon Transcribe – Accurate Speech To Text At Scale.
AWS Comprehend
Amazon Comprehend is a natural language processing (NLP) service that uses machine learning to find insights and relationships in text. Amazon Comprehend identifies the language of the text; extracts key phrases, places, people, brands, or events; understands how positive or negative the text is, and automatically organizes a collection of text files by topic. – AWS Service Page
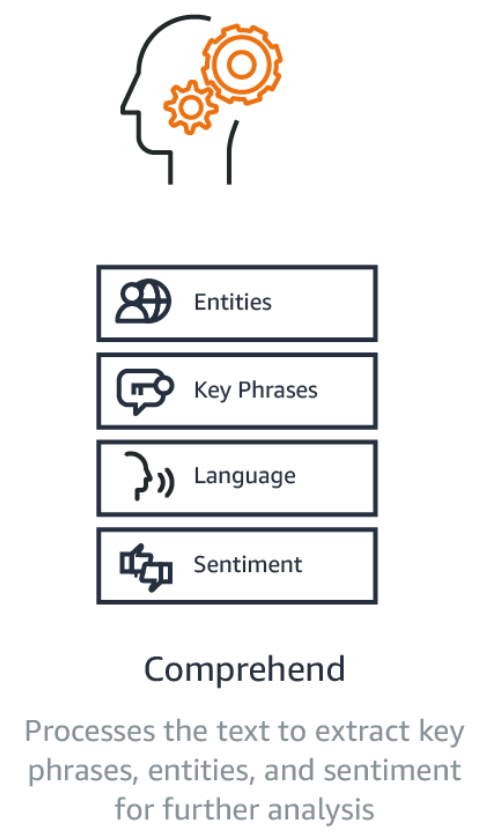
It analyzes text and tells you what it finds, starting with the language, from Afrikaans to Yoruba, with 98 more in between. It can identify different types of entities (people, places, brands, products, and so forth), key phrases, sentiment (positive, negative, mixed, or neutral), and extract key phrases, all from a text in English or Spanish. Finally, Comprehend’s topic modeling service extracts topics from large sets of documents for analysis or topic-based grouping. – Jeff Barr – Amazon Comprehend – Continuously Trained Natural Language Processing.
Instead of AWS Comprehend, you can use similar services to perform Natural Language Processing, like: Google Cloud Platform – Natural Language API or Microsoft Azure – Text Analytics API.
I prefer to use AWS Comprehend because the service constantly learns and improves from a variety of information sources, including Amazon.com product descriptions and consumer reviews – one of the largest natural language data sets in the world. This means it will keep pace with the evolution of language and it is fully integrated with AWS S3 and AWS Glue (so you can load documents and texts from various AWS data stores such as Amazon Redshift, Amazon RDS, Amazon DynamoDB, etc.).
Once you have a text file of the audio recording, you enter it into Amazon Comprehend for analysis of the sentiment, tone and other insights. Instead of AWS Comprehend, you can use similar services to perform Natural Language Processing, like: Google Cloud Platform – Natural Language API or Microsoft Azure – Text Analytics API.
> Here you can find an AWS Comprehend use case: How to Combine Text Analytics and Search using AWS Comprehend and Elasticsearch 6.0.
Conclusion
In this post we have seen a system architecture that performs the following:
- Speech to text task – AWS Transcribe
- Text analysis – AWS Comprehend
- Index and fast search – Elasticsearch
- Dashboard visualization – Kibana
- Automatic Reporting and Alerting – Skedler Reports and Alerts
Amazon Transcribe and Comprehend can be powerful tools in helping you unlock the potential insights from voice and video recordings that were previously too costly to access. Having these insights makes it easier to understand trends in issues and consumer behavior, brand and product sentiment, Net Promoter Score, as well as product ideas and suggestions, and more.
In the next post (Part 2 of 2), you can see how to implement the described architecture.


