
June 26th, 2023
eBPF: Transforming Observability as We Know It
What is eBPF
eBPF (extended Berkeley Packet Filter) is a powerful technology that extends the capabilities of the Linux kernel by allowing developers to dynamically extend its functionality without directly modifying the kernel source code.
It was originally developed for Linux, but Microsoft is rapidly evolving with the implementation of this technology for Windows. Its popularity has increased in recent years because it allows visibility and control of system behavior that is very useful for the developer’s work.
Today, companies of all types and sizes use eBPF. Also, some large companies such as Google, Netflix, Android or Meta use eBPF in production for different purposes. You can find some very useful case studies on the official eBPF website.
In the current era, the use of this revolutionary technology is becoming even more widespread. Watch this video by Alexei Starovoitov, co-creator of Linux and co-maintainer of eBPF, on the evolution of eBPF.
Why Is eBPF So Important?
In the Linux operating system, memory is divided into two distinct areas: kernel space and user space. The kernel space houses the main components of the operating system and has privileged access to hardware resources, including memory, storage and CPU.
On the other hand, the user space is where the usual applications and processes run. The user space code operates with limited access to hardware and relies on system calls, which are kernel APIs, to perform privileged operations such as disk or network input/output. However, in certain cases, developers may need more flexibility to introduce new file systems, add support for new hardware or implement custom system calls.
This is where eBPF comes into play. Historically, changing anything in the kernel source code or operating systems layer was a complicated task. Thanks to eBPF, by loading eBPF programs directly into the kernel, developers can extend its capabilities in a safe and controlled manner. These programs run inside the kernel space, allowing precise control of network traffic, system monitoring, security filtering and various other operations.
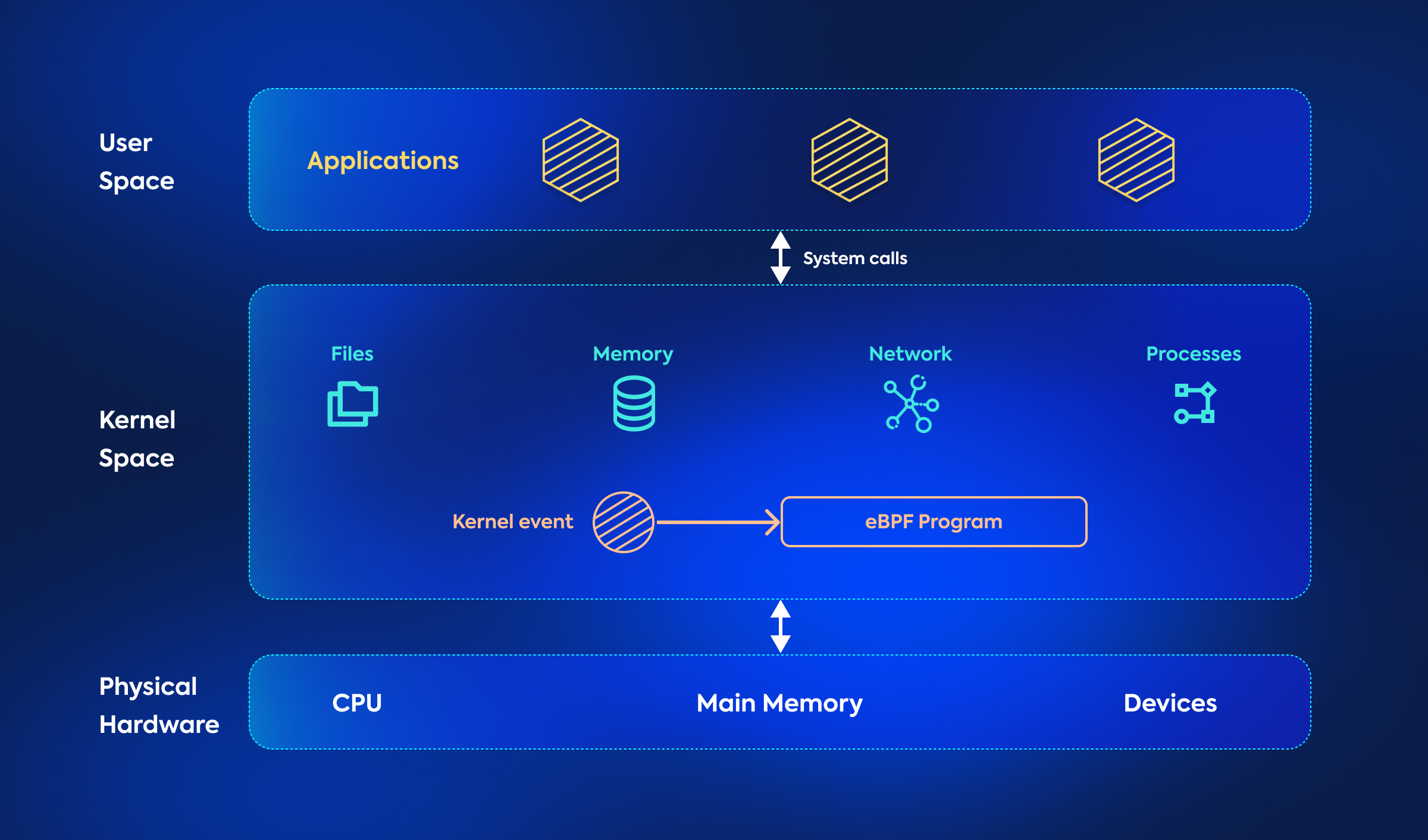 As a result, this is a very powerful technology with the potential to significantly change the way services such as networking, observability and security are delivered.
As a result, this is a very powerful technology with the potential to significantly change the way services such as networking, observability and security are delivered.
How eBPF Works
eBPF works by running programs written in a low-level assembly-like language, called eBPF bytecode, on a virtual machine within the Linux kernel. These programs can be created by developers and system administrators to monitor and analyze specific system events.
The general procedure for ejecting an eBPF program goes like this:
- The developer writes a program in a high-level language using an eBPF API.
- The program is compiled into eBPF bytecode and used in a compiler such as LLVM.
- The eBPF bytecode is loaded into the Linux kernel using an eBPF loading tool, such as bpftool or bpftrace.
- The kernel executes the eBPF program in the eBPF VM, monitoring and analyzing system events as defined by the program.
- The results of the eBPF program are reported as a user space for analysis and visualization.
Now that we know how it works, we can ask ourselves: what is it used for? what are the case uses of this technology? As mentioned above, more and more companies are using this technology, as it is useful for a wide range of use cases, including:
- Monitoring and analyzing system performance
- Analyzing red packet traffic and filtering
- Tracking system calls and hardware events
- Implementing security and access control policies
- Debugging and troubleshooting system problems
What Are Its Benefits?
When it comes to system observability, the ability to adapt to diverse needs and environments is critical. This is where this technology shines, providing an unprecedented level of flexibility to developers and system administrators. The versatility eBPF offers opens up a world of possibilities, allowing organizations to extract valuable information from their systems in a way that precisely aligns with their goals and objectives. Here are the benefits of this technology:
Flexibility: it allows developers and system administrators to create custom programs to monitor and analyze specific system events, providing great flexibility to suit individual needs.
Performance: Because eBPF programs run directly in the Linux kernel, they can monitor and analyze system events with minimal overhead, enabling real-time performance analysis without significantly impacting system performance.
Security: it uses a security checker in the kernel to ensure that eBPF programs cannot cause system damage or compromise security. This allows developers and system administrators to run eBPF programs with confidence, knowing that they will not compromise system stability or security.
Portability: eBPF programs are independent of system architecture, which means they can run on different Linux systems without modification.
Strict verification: Before any eBPF program can be loaded into a kernel, it is verified by the eBPF verifier, ensuring that the code is absolutely safe.
Sandboxed: eBPF programs run in a sandbox with isolated memory inside the kernel, separated from other kernel components. This prevents unauthorized access to kernel memory, data structures and kernel source code.
Fast execution and good performance: Running as native machine instructions on the CPU results in faster execution and better performance.
No context switches: A normal application switches context regularly between user space and kernel space, which requires a lot of resources. Since its programs run in the kernel layer, can directly access kernel data structures and resources.
Event-driven: it programs generally run only in response to specific kernel events rather than always being active. This minimizes overhead.
Optimized for hardware: The kernel’s Just-In-Time (JIT) compiler compiles the programs into machine code just before execution, so the code is optimized for the specific hardware on which it runs.
Revolutionizing Observability: The Power of eBPF
In short, eBPF can be used for almost all existing common observability use cases and opens up new possibilities. It can enhance network observability, Kubernetes observability, security observability and performance observability. In fact, it emerged as a popular choice for implementing observability in the kernel of end hosts, due to its performance and flexibility. As an example, Google processes most of its data center traffic through this technology, using it for security and runtime observability.
The reason behind this is the following: everything goes through the core. And this technology provides a secure, high-performance way to observe everything from the kernel.
Of the four components of observability (data collection, data processing, data storage, and user experience layer), eBPF especially impacts the data collection layer: the easy collection of telemetry data directly from the kernel using eBPF. So, what we mean when we say “eBPF observability” today is that we use this technology as an instrumentation mechanism to collect telemetry data, rather than using other methods.
In order to understand the mechanics behind eBPF observability, it is crucial to grasp the concept of hooks. These hooks serve as triggers for eBPF programs, which are event-based and capture data for observational purposes whenever specific events occur. These hooks can exist in both kernel space and user space, allowing monitoring of user-space applications as well as kernel-level events. In addition, these hooks can be statically or dynamically inserted into a running system, eliminating the need to reboot the system.
There are four different mechanisms in eBPF that facilitate the use of hooks:
- Kernel tracepoints: allow connecting to predefined events set by kernel developers.
- USDT (User Statically Defined Tracing): allows developers to define tracing points in the application code for eBPF programs to connect to.
- kprobes (Kernel Probes): provide the flexibility to dynamically hook to any part of the kernel code at runtime.
- uprobes (User Probes): allow dynamic connection to specific functions within user-space applications without modifying their code, providing powerful observation capabilities, including live debugging.
New applications of this technology in observability are emerging every day. In the coming years, this technology is expected to drive a lot of innovation in this space and make observability safer and easier to implement.
Conclusion
It is quite feasible that in the coming years this technology will play a pivotal role in transforming the current approach to observability. As new applications of eBPF in observability continue to emerge, it is clear that this revolutionary technology will drive innovation and shape the future of observability. Its ability to provide a safer and simpler implementation of observability will be critical to improving system performance, safety and overall operational efficiency.
If you enjoyed this article, we invite you to visit Skedler’s blog to find other articles on observability, DevOps, artificial intelligence, and more. We also invite you to try Skedler, our reporting automation tool.


